
Bu yazıda bir süredir değinmek isteyip fırsat bulamadığım bir konudan bahsedeceğim. Zira, birkaç gün önce gerçekleşen Google Gemini lansmanı bunun için son derece elverişli ve sıcak bir örneğe dönüştü.
Hem dünyada hem de beni daha çok ilgilendiren tarafıyla ülkemizde, yapay zeka sahasındaki gelişmelerin geniş kitlelere aktarılmasıyla ilgili son derece problematik bir durum var. Bunu soyut olarak ele almak yerine sıcak gündem olan Gemini örneği üzerinden anlatmak istiyorum.
Google’ın Gemini serisinin duyurulması, buna yönelik iletişim ve ortaya çıkan PR felaketini daha iyi anlayabilmek için kısaca bu noktaya kadar yaşananları hatırlamakta fayda var. Eğer bugün yaşanan durumu geçmişiyle birlikte anlamak istiyor ve Google’ın üretken yapay zeka sahasındaki karnesini merak ediyorsanız önce şu yazımı okumanızı öneriyorum:
Eğer buna vaktiniz yoksa gelin doğrudan Gemini örneğinden yola çıkarak genel problemin ne olduğunu konuşalım.
Gemini Neden Önemli ?
30 Kasım 2022’de ChatGPT ara yüzü üzerinden ilk defa eriştiğimiz GPT 3.5 ve Mart 2023’te lansmanı yapılan GPT-4, üretken yapay zeka ekosisteminin gördüğü en önemli atılımlardan ikisini temsil ediyorlar. OpenAI tarafından geliştirilen ve hizmete sunulan GPT serisi, dil modelleri cephesinde tartışmasız şekilde “state-of-the-art” düzeyi örnekliyorlar. Bunu değiştirmeye en yakın aday olarak ise Google’ın çalışmaları görülüyordu. OpenAI, Kasım 2023’teki DevDay etkinliğindeki yeni eklemeleriyle bu alandaki yerini perçinlerken gözler iyiden iyiye Google’a çevrilmiş ve Google üzerindeki beklenti/baskı daha da artmıştı. Gemini, uzun süredir beklenen ve “Nokia’ya karşı iPhone Moment” yaratması hayal edilen bir sürecin ardından doğdu. Belki de şimdi bahsedeceğimiz sorunlu lansman iletişimi, bu büyük beklenti altında ezilen bir sürümü gizleme çabasından kaynaklıydı.
Gemini Lansmanı ve PR Felaketi
Gemini lansmanıyla ilgili farklı tarihler konuşulduktan sonra son dedikodular modelin lansmanının 2024’e kaydırıldığı yönünde yayılmıştı. O yüzden 6 Aralık 2023’te Gemini serisinin çıkış yapması biraz sürpriz de oldu. Beklenti bu kadar yüksek, lansmanı yapan marka Google, model ailesini geliştiren de Deepmind ekibi olunca elbette büyük bir heyecan dalgası yükseldi. “Bu defa GPT-4’ü aşan bir model geldi” ana fikri sorgulanmaksızın tekrarlanmaya ve konuyu değerlendirecek uzmanlığı olmayan pek çok kişi ya da medya platformu tarafından derhal paylaşılmaya başlandı. Öyle ki benim de başarılı bulduğum bazı mecralarda “Yapay Zeka’da Yeni Bir Çağ Açıldı” başlıklı paylaşımlar dahi boy gösterdi.
Gemini lansmanı benim için de son derece heyecan yaratan bir gelişmeydi. Ben de bu heyecanımı hem meslektaşlarımla hem de sosyal medya hesabımdan kamuoyuyla paylaştım elbette. Fakat bu sahayı yalnızca bir “etkileşim kaynağı” olarak görmeyen, bu sahada insanlık için değer yaratılabileceğine inanan her uzman gibi şerhlerimi de baştan düştüm.

Etkileyici demoları takip eden her uzmanın anında fark ettiği “gerçekçi gelmeyen” unsurlar vardı. Ancak yine de bu defa Google, “söz konusu teknolojinin tavanı / potansiyeli neye benziyor?” sorusuna tatmin edici yanıtlar içeren materyaller üretmeyi başarmıştı. Paylaşılan içeriklerin ilettiği mesajlar ve materyallerin kurgusu son derece başarılıydı. Küçük bir sorun vardı: Gösterilen ile gerçeklik arasındaki büyük fark.
Gemini Hakkında Ne Biliyoruz?
Deepmind gibi bir ekibin elinden çıkan her iş bugüne kadar başarılı oldu. O yüzden Gemini serisinin mutlaka katkı sağlayacağına eminim. Bildiklerimiz şöyle:
- Gemini Ultra modelini henüz kendimiz deneyemiyoruz. En büyük ölçekli ve doğal olarak en geniş yeteneklere sahip olacak varyant da Ultra. O yüzden bir “devrim” gelecekse bile bu ancak Ultra ile olacaktı ve şu anda bağımsız geliştiriciler ya da son kullanıcılar bu modeli görmüş değil. Üretken yapay zeka tarafındaki kesin kurallardan biri “Access or didn’t happen” / “Kendim denemeliyim ya da öyle bir şey yok” 🙂 Bunu unutmamak gerek.
- Elimizde Gemini serisinin, yaygın kullanılan benchmark’lardan aldıkları skorları gösteren resmi bir Google raporu var. Burada raporlanan skorları birazdan inceleyeceğiz. Benchmark skorları, pratik durumlarda yaratılan değeri tam olarak yansıtmasa da dil modellerini kıyaslamak açısından önemli yöntemlerden birisi.
- Benim de asıl dikkat edilmesi gereken yön olduğunu düşündüğüm, Gemini serisinin “natively multi-modal” olarak tasarlandığı bilgisine sahibiz. Zaten son kullanıcıları asıl heyecanlandıran örnekler de çoklu form senaryosunda modelin performansını yansıttığı ileri sürülen demolar oldu. Bu demolarla ilgili problemlere de aşağıda değineceğiz.
- Resmi rapordan öğrendiğimiz kadaryla Gemini serisi için bağlam penceresi 32k token olarak bildiriliyor. Kasım ayında GPT-4’ün 128k token’a yükseltildiğini düşündüğümüzde burada geliştiriciler olarak biraz hayal kırıklığı yaşadığımızı söyleyebiliriz. Bununla birlikte, dikkat mekanizmasının etkin çalışması halinde 32k uzunluk birçok senaryo için iş görebilir.
- Magazin değeri anlaşılamadığı için daha az bahsedilse de aslına Gemini serisinin getirdiği en merak uyandırıcı değer önermelerinden birisi Gemini Nano varyantlarının “on-device” olarak çalışmak üzere tasarlanmış olması. Dil modellerinin en önemli sınırlılıklarından birisi bulutta ve yüksek işlem gücü gereksinimleriyle sunulmaları. Bu yüzden kendi cihazlarımızda çalıştırabileceğimiz dil modelleri, bu alanda gerçekten “devrimsel” fark yaratmak için en önemli senaryolardan biri. Google, Gemini ile belirli yetenekleri mobil cihazlara getirmeyi vaat ediyor ki bu çok önemli bir test olacak. İlk aşamada kendi cihazları olan Pixel 8 Pro’da, Gemini Nano’nun gücünü görebileceğiz gibi duruyor.
Sonraki bölümde ise Gemini lansmanını neden bir PR Felaketi olarak nitelediğime değineceğim.
Google Gemini Demo’ları ve Ters Tepecek İletişim Kampanyası
Problematik durumlara bakalım:
1) Ortada bir “devrim” ya da yeni bir “SOTA” olduğuna dair elimizde done yok. Resmi raporda paylaşılan benchmark skorlarını ve resmi duyuru blogunu yakından inceleyince pek çok uzman aynı şeyi fark etti. Google, resmi blog sayfasında Gemini modelini tanıttığı yazıda, okuyucuları yanlış yönlendiren bir detay paylaştı. Aşağıdaki ekran görüntülerinden solda yer alan blogdaki içerik, sağdaki ise resmi rapordaki orijinal kıyas tablosundan:
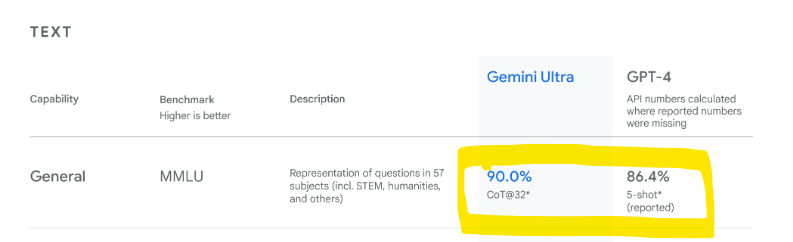
Google Blogdaki Tablo
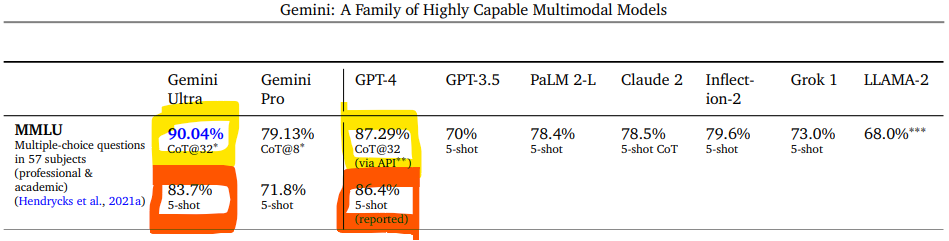
Gemini Raporundaki Tablo
Google’ın kendi modelinin “state-of-the-art” olduğu iddiasına argüman olarak, kendi raporuyla dahi uyuşmayan, yanıltıcı bir argüman paylaşması akıl alır gibi değil. Yaptıkları şey özetle şöyle; en önemli benchmark testlerinden biri olan MMLU performansında Gemini Ultra, GPT-4’ü geçemiyor. (5-Shot senaryosu) Bu yüzden de kendi tanımladıkları başka bir teknikle (CoT@32) daha GPT-4 ve Gemini Ultra’yı kıyaslıyorlar. Burada Gemini önde görünüyor. Fakat blog yazısında elmalarla armutları kıyaslıyorlar. Gemini modelinin CoT performansıyla GPT-4 modelinin 5-Shot performansını kıyaslayıp bunun üzerinden “SOTA” iddiası dillendiriyorlar. Gerçekten şaşkınlık verici. Bunun basit bir “sehven” yazım olmadığı ortada. Zira, bu durumu halen (09.12.2023 itibarı ile) düzeltmedikleri gibi, Google’ın Baş Araştırmacısı olarak görev yapan Jeff Dean’in aşağıdaki twitter yazışması da ne yaptıklarının gayet farkında olduklarını doğruluyor:
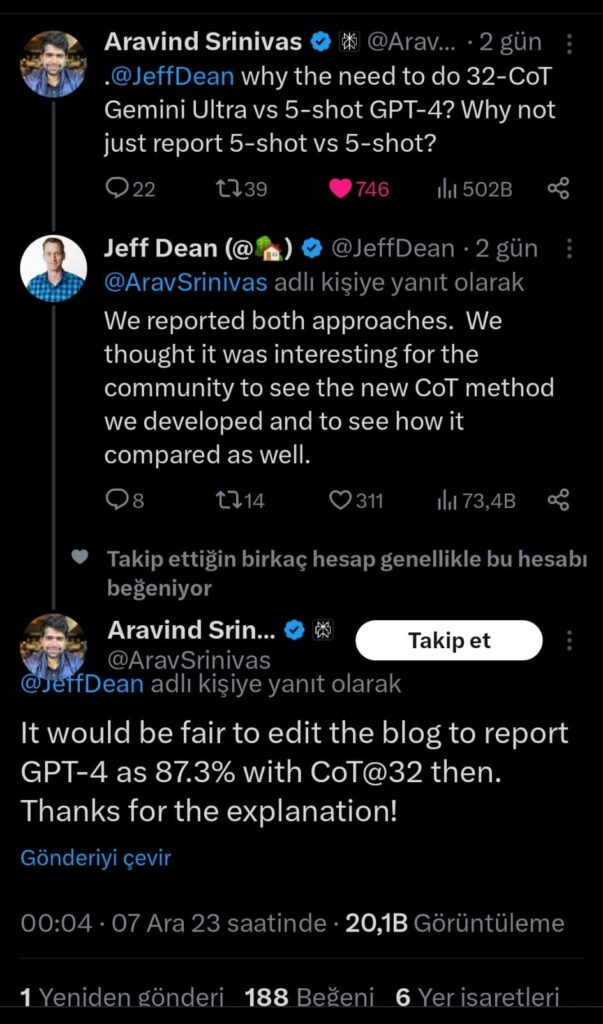
Başarılı bir üretken yapay zeka start-up’ı olan Perplexity AI CEO’su Aravind Srinivas, durumu doğrudan Jeff Dean’e soruyor. Aldığı yanıt “Biz iki yaklaşımı da raporladık. Geliştirici komünitesinin, yeni geliştirdiğimiz CoT metodunu ve kıyaslamada ne durumda olduğunu görmesinin ilginç olacağını düşündük“. Jeff, blogdaki elma armut kıyasına hiç değinmeyip raporda her ikisinin de bildirildiğini söyleyince Aravind haklı olarak blogdaki yazının elma vs elma olarak düzeltilmesinin daha adil olacağını söylüyor. Ve Jeff Dean’den başka bir yanıt gelmiyor. Çünkü Jeff arasında satır arasında söyleyeceğini söylemiş. “Biz raporda her ikisini de raporladık”. Blog kısmı ise artık “PR” katmanına dahil ve bu işi kim yönetiyorsa büyük çuvallamış durumda. Öyle ki Google’ın baş araştırmacısına söyleyecek söz bırakmadılar.
Yalnız buradaki gariplik bununla da kalmıyor. Jeff Dean, raporda aynı senaryolardaki kıyaslamaları raporladıklarını söylerken haklı fakat başka bir sorun daha var. Geçmeye çalıştıkları GPT ile ilgili eldeki veri 5-Shot bir senaryoya ait. Bu senaryoda rakiplerini geçemiyorlar. Rakibi geçemeyince kendi tanımladıkları bir başka senaryo daha çıkıyor karşımıza: CoT@32. Ve ne ilginçtir ki “SOTA” olma iddiasının neredeyse tek temeli olan bu skoru elde ettikleri CoT@32’nin ne olduğuna, bu tanım altında nasıl bir test yaptıklarına dair tek bir kelime dahi yok Gemini teknik raporunda. Okuyucu olarak bağlamdan yola çıkarak CoT kısaltmasının “Chain of Thought” yaklaşımını işaret ettiğini düşünüyoruz. Bu, gelişmiş prompt engineering tekniklerinden birisi. Belli ki Google ancak kompleks bir prompt engineering yaparak GPT-4’ü geçmeyi başarabilmiş. Fakat Chain of Though bir yaklaşımın adı ve bunu hayata geçirmenin pek çok farklı yöntemi var. O yüzden aslına bakarsanız, tam olarak ne yaptıklarını da anlayamıyoruz. “32” kısmı, 32 aşamalı bir düşünce zinciri işlettikleri anlamına geliyor olsa gerek. Uzun lafın kısası, büyük bir iddiaya delil olarak sundukları kavramı açıklamak şöyle dursun, tam adını bile yazmadan raporlayıp, resmi blog sayfasında da göz göre göre çarpıtma yapan bir Google görmek üzücü.
NOT: Google’ın lanse ederken bu kadar “dolambaçlı” yollar izlemek zorunda kaldığı Gemini serisi için iddia edebildiği çıta da (her şey doğru olsa bile) GPT-4’ün birkaç yüzdelik puan ötesine uzanabilmiş durumda. Benchmarklar esnasında oluşabilecek ölçüm hatalarıyla bile açıklanabilecek bu kadar dar bir marjin de büyük hayal kırıklığı yaratıyor. Çünkü kıyaslama yapılan GPT-4 yaklaşık 8 ay önce tamamlanmış bir proje. Aradan geçen 8 ayda Google radikal bir fark yaratmayıp, belli nüanslarla ancak GPT-4 seviyesine ulaşabildiği noktada apar topar lansman yapmak durumunda kalmış gibi görünüyor.
Nitekim bu mum yatsıya kadar bile yanmadı. Bard üzerinden deneyebildiğimiz Gemini Pro varyantı herhangi bir “üstün performans” ışıltısı vermedi. Google’ın bu süreçte şeffaf olmaktan kaçınmasına bakınca, Gemini Ultra’ya dair de farklı bir beklenti içine girmek çok anlamlı durmuyor.
2) Çoklu form cephesinde de büyük bir hayal kırıklığı var. Blogunda çarpıtma yapan Google, demo videolarında ise düpedüz kullanıcıları kandırmış gibi görünüyor. Daha ilk izlemede bu videodaki gerçekçi olmayan detayları ben de fark etmiştim. Yukarda ekran görüntüsü yer alan Linkedin postumda belirttiğim gibi buradaki yanıt süreleri ve insan tarafından verilen sesli komutlara karşılık hatasız/incelikli cevapların ilk seferde üretilmesi gerçek olamazdı. Dil modellerinin auto-regressive yapısını, bir transformer’ın nasıl çalıştığını, inference ile ilgili fiziksel sınırlılıkları bilen hiçkimsenin zaten buna inanması mümkün değildi. Fakat buradaki Bloomberg makalesinde harika biçimde özetlendiği şekilde, videodaki problemler bununla sınırlı değildi.
Doğrusu, sadece yanıt sürelerini olduğundan daha kısa göstererek bir demo yapılmasını bir noktaya kadar kabul edebiliriz. Çok emek verdikleri bir servisi tanıtırken ilgiyi yükseltmek adına tüm şirketler bazı “cilalama”lar yapar. Örneğin ortalama olarak 10 saniye süren yanıt sürelerini videoda “neredeyse anlık” gibi sunan bir demoya o kadar da fazla tepki göstermeyebilirdik. Zira, inference tarafında yaşanabilecek gelişmelerin bizi böyle bir performansa yaklaştırması mümkün. Daha iyi donanım hızlandırıcıları, daha iyi paralel mimariler, daha optimize modeller ile bu yöne doğru gidilebilir.
Fakat “prompting” kısmında herhangi bir müdahale yapılması kabul edilemez. Çünkü dil modellerini etkileyici kılan, bu videoyu da dikkat çekici kılan, nokta doğal dilde sunulan girdileri anlamlandırabilme kabiliyetleri ve sofistike yanıtlar üretebilmekteki performansları. Fakat Google, videode gördüğümüz çıktıları, videoda gördüğümüz girdilerle elde etmediğini kabul ediyor. Nasıl bir prompting stratejisi izlediklerini de açıklamışlar sağolsunlar(!) Yani video gördüğünüz gibi, içinizden geldiği şekilde konuşmuyorsunuz Gemini ile. Daha vahimi, Gemini modelinin size verdiği yanıtlar da videoda gördüğünüz yanıtlar değil. Google’ın resmi Youtube kanalında paylaşılan videonun açıklamalar kısmında şu ifade var: “Gemini outputs have been shortened for brevity” yani “Gemini modelinin çıktıları daha öz olmaları için kısaltılmıştır” (Şaka gibi). Hiç uzatmadan bunun Türkçesini söyleyeyim: “Demo’nun etkileyici görünmesi için modelin o spesiifik senaryoda alacağı girdilerin ne olması gerektiğini uzun uzun çalıştık sonra da çıktıları sizi etkileyecek şekilde olmaları için kafamıza göre kesip biçtik“.
Bir teknoloji devinin böyle bir şeye tevessül ederken yakalanması size vahim geliyorsa henüz bekleyin. Girdi-çıktıları düzenlemiş olmalarından daha fena bir şey de var. Söz konusu demoda bizi en çok hayran bırakan şeylerden birisi, bir insanın bir yapay zeka modeliyle yaptığı sesli sohbetin doğallığı ve akışkanlığıydı. Ben de kendi mesajımda “ayarlamalar” bariz olmasına rağmen çoklu formun potansiyeline dair çok güzel bir kompozisyon olarak değerlendirmiştim. Meğer ortada işitsel bileşen yokmuş. Evet, hiç yokmuş. Buradaki belki de tek “yeni” gelişme olan görsel ve metinsel forma sesin de eklenmesi tamamen düzmece imiş. İzlediğimiz şey bir “seslendirme”. Dümdüz metin olarak yazılan girdilere modelin metin olarak verdiği cevapları bildiğiniz seslendirmişler. Ve bunu bize “demo” olarak sunmuşlar. Bu kadarı gerçekten artık saygısızlık düzeyinde bir çarpıtma. Çünkü böyle bir demo yayınladığınızda, STS (speech-to-text) ve TTS (text-to-speech) alanlarında da “state-of-the-art” denebilecek yetkinliklere ulaştığınızı iddia etmiş oluyorsunuz. Metin tabanlı bir etkileşimi tiyatral bir performansla seslendirip sunamazsınız.
Bu arada gerek Bloomberg makalesinde gerek farklı mecralarda eleştirilen bir diğer nokta da Gemini modeline bir videonun değil resim karelerinin girdi olarak verilmesi ve modelin bu resim karelerine dayalı yanıtlar üretmesi. Fakat burada eleştiriyi hak edecek pek bir şey yok. Multimodal sistemlerle çalışma deneyimi olan kimse böyle bir eleştiri yöneltmez. Zaten çoklu form derken henüz kimse akan bir videodan (streaming) yola çıkarak modelleri çalıştırmaktan bahsetmiyor. Bu tür uygulamalarda standart yöntem, videodan belirli aralıklarla kesit alarak bu kareleri prompt’a eklemek suretiyle modeli çalıştırmak şeklinde. O yüzden girdinin video değil de sabit resimler olmasıyla ilgili eleştiri yersiz olmuş. Çoklu form etkileşimlerde videoları dahil etmek için kullanılacak yaklaşım budur.
Bu kadar detaydan sonra herhalde izlediğimiz şeyin, bize gösterildiği gibi “gerçek zamanlı bir yayın” olmadığını kaydedilmiş bir görüntüye sonradan seslendirme eklenmesiyle oluşturulmuş bir video olduğunu söylememe gerek yoktur… Bu detayları birleştirince, neden OpenAI ekibinin yaptığı gibi bir insanın, izleyici kitlesi önünde gerçek zamanlı olarak modelin yeteneklerini gösterdiği demo etkinliklerini iptal ettiklerini de anlamış oluyoruz.
3) Aslında bu madde de yine meşhur(!) çoklu form videosundaki bir çarpıtmaya dair olacak. Fakat burada videonun genel yapısıyla ilgili problemlerden değil spesifik bir kısmıyla ilgili bir problemden bahsedeceğiz. Resmi demo videosunun yaklaşık ikinci dakikasından itibaren gösterilen “Game Creation” örneğinden bahsediyoruz.
Doğrusu en çok bu kısma üzüldüm. Tüm demo içinde benim en çok sevdiğim yer burasıydı. Yukarda ilgili bölümü izleyebilirsiniz. Özetle şunlar oluyor; demodaki insan (ya da sonradan seslendiren kişi mi demeliyiz?) bir dünya haritası resmi gösteriyor ve buna bakarak bir oyun fikri düşün diyor Gemini modeline. Ek bir talebi daha var. Emoji kullanılsın istiyor. Gemini da “Ülkeyi Tahmin Et” adına bir oyun icat ediyor. Buna göre, yapay zeka modeli söz konusu ülke hakkında ipuçları veriyor, insan da tahmin ettiği ülke üzerine parmağını yerleştirerek yanıt veriyor. Gemini yanıtın doğru mu yanlış olduğuna karar verip geri bildirimde bulunuyor. Hem içerdiği yaratıcılık seviyesiyle hem akıcı biçimde ses – görsel – metin birlikteliği sağlıyor olmasıyla “ilham verici” bulduğum bir örnekti. Ancak burada da hayal kırıklığına uğruyoruz.
Google’ın prompting stratejilerini sağolsunlar(!) yine bizimle paylaştığı sayfadan inceleyelim:
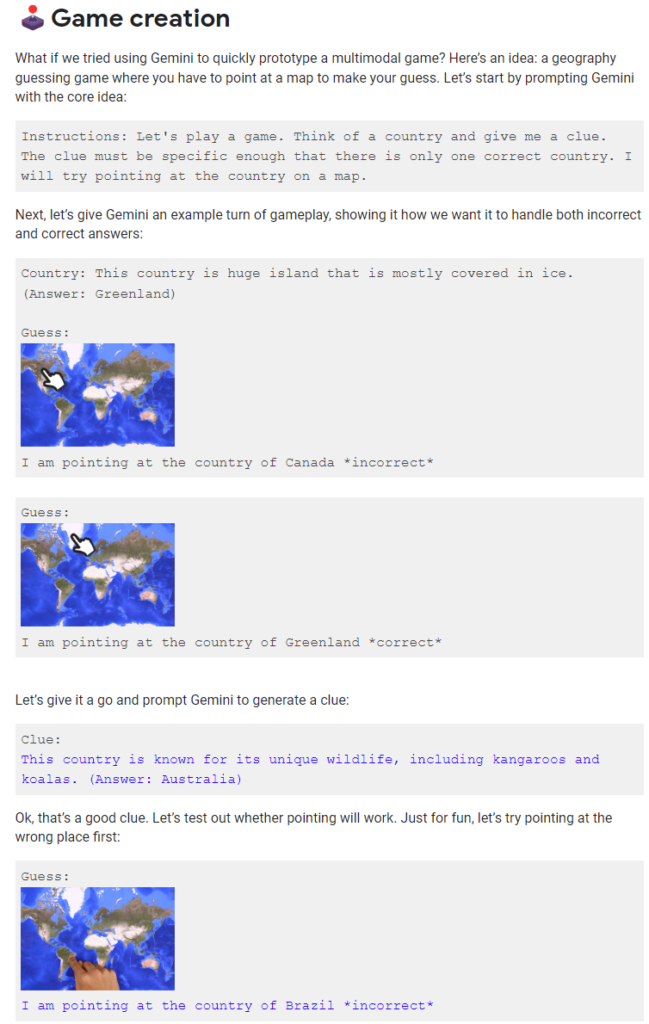
Bir defa oyunun ana fikri -ki yeni olan nokta da oydu- model tarafından icat edilmiyor. Oyunu açıkça tarif ediyorlar Gemini modeline.
Dahası oyunu tam olarak anladığından emin olmak için few-shot prompting uyguluyorlar. Yani modele doğru ve yanlış örnekler üzerinden, doğru davranış biçimini de öğretiyorlar.
Teşekkür ederiz Google. Fakat biz nasıl few-shot prompting yapabileceğimizi de bir oyun fikrini bir dil modeline nasıl kavrattırabileceğimizi de zaten biliyorduk.
“Yaratıcı” bir fikir üretebilen ve bunu da destek almaksızın icra edebilen bir model ürettiğinizi sandığımız için heyecanlanmıştık.
4) Son olarak bir noktaya daha değinmekte fayda var. Bir “devrim” hatta bazılarına göre “yeni bir çağ” olarak pazarlanan/algılanan demo’larda, onca çarpıtmayı bir kenara koyunca bile, sanıldığı kadar etkileyici bir durum söz konusu değildi zaten. Şaşkınlığın ve hayranlığın çoğu, bu sahadaki gelişmeleri yakından takip edememesi gayet normal olan son kullanıcıların, çoklu form senaryolarıyla neler yapılabildiğini, güzel toparlanmış bir derleme halinde arka arkaya görmemiş olmasından kaynaklıydı. Google’un en iyi başardığı şey, çoklu form yeteneklerinin nereye ulaştığına dikkat çekmek oldu.
Fakat bunların büyük çoğunluğu “yeni” değildi. Yeni olanların da “gerçek” olmadığı anlaşıldı. Neyse ki bu işe mesai ayıran iki akademisyen örneklendirdi bu durumu. Meşhur videodaki “ördek” ve “oyun” örneklerinde gördüğümüz çoklu form algılama kabiliyetinin GPT-4 V’de zaten var olduğunu Ethan Mollick’in iletilerinde görebilirsiniz. Bu arada her gelişmeyi “kral öldü yeni kral” havasında servis eden “AI Shitposter”lar yerine Ethan’ı takip etmenizi şiddetle tavsiye ederim 🙂 Bir diğer örnekte de University of Wisconsin-Madison’da görev yapan Dimitris Papailiopoulos demo’larda geçen 14 senaryonun 12’sini GPT-4 V ile hayata geçirebildiğimizi gösteren güzel bir seri paylaştı.
Son Söz
Doğrusu Gemini için büyük umutlar besliyordum. Dil modellerini ChatGPT, Bard, Claude Chat, Pi, Poe gibi basit sohbet ara yüzlerinde kullanmanın ötesine geçtiğinizde transformer mimarisinin içkin sınırlılıkları epey canınızı sıkmaya başlıyor. (halüsinasyonlar, bağlam penceresi, tutarlılık, maliyetler, opsiyonsuzluk vb) Elbette her biri için “workaround”lar var. Ama tüm bunları geliştrici yerine modelin halletmesini istiyoruz elbette 🙂
Umut vaat eden çok fazla süreç bulunmakla birlikte “hazır” durumdaki teknolojilerin olgunlaşması için tek çare rekabet. Bu perspektiften bakınca Google Gemini serisi, yakın vadedeki en önemli meseleydi. Önümüzdeki 1-1,5 yıl içinde bir GPT-5 görüp görmeyeceğimiz, Amazon ve Apple’ın bu konuda atacağı adımların büyüklüğünün ne olacağı, açık kaynak çalışmalarına verilecek desteğin artması gibi pek çok kritik konuda fark yaratabilecek en büyük aday Gemini serisi idi. Deepmind ekibinin bu mesele için büyük gayret gösterdiği ortada. Doğru ve gerçekçi bir iletişim kampanyasıyla pekala GPT serisinin en ciddi alternatifi/rakibi olmak için gerekli her şeye sahip gibi duruyor Gemini modelleri. Fakat Google’ın başka alanlardaki (yönetim, değerleme, marka algısı, kurum kültürü vs) problemlerinden doğan baskılar Gemini modeline “lekeli” bir başlangıç yaptırmış durumda. Bu demo fiyaskosu ve her habere abartıyla yaklaşan teknoloji medyası/sosyal medya aktörlerine rağmen, 13 Aralık 2023’te deneyebilmeyi umduğumuz Gemini Ultra gerçek testi, yani bizzat yapacağımız denemeleri, başarıyla kotarırsa, Deepmind’ın emekleri boşa gitmiş olmayacak.
Bu İçeriği Paylaş: