Üretken Yapay Zeka teknolojisinin tarihsel gelişimi:
1989-1998

LENET Serisi
Bu serinin son halkası olan LENET-5, Evrişimsel Sinir Ağlarının ilk örneklerinden biriydi. Hem el yazısı hem matba baskısı harfleri okumak, ayırt etmek için geliştirilmişti. Yapay Zeka sahasının önde gelen isimlerinden Yann LeCun‘un, önemli çalışmalarından birisi olarak tarihte yerini aldı. İlk örneği 1989’da ortaya çıkan modelin 1998’de Lenet-5 ile olgunluğa ulaştığı söylenebilir.
2009

IMAGENET
Üretken Yapay Zeka teknolojisinin bugünlere gelmesindeki önemli köşe taşlarından birisi hiç şüphesiz IMAGENET projesiydi. Fei Fei Li ve ekibinin IMAGENET için harcadıkları emek ve ortaya koydukları vizyon, kendi beklentilerini dahi aşan bir zincirleme reaksiyon başlattı. Bilgisayarlı Görü (Computer Vision) alanındaki hızlı ilerlemeleri IMAGENET’e borçluyuz. IMAGENET çalışmaları kapsamında 14 miyondan fazla görsel, insanlar tarafından incelenip etiketlendi. O dönem için benzeri görülmemiş büyüklükte bir veri etiketleme hareketiydi bu. Böylece “IMAGENET Challenge” ortaya çıkmış oldu. Bu veriseti üzerinde eğitilen sonraki modeller, etkileyici yeni ihtimallerin kapısını araladı.
2012
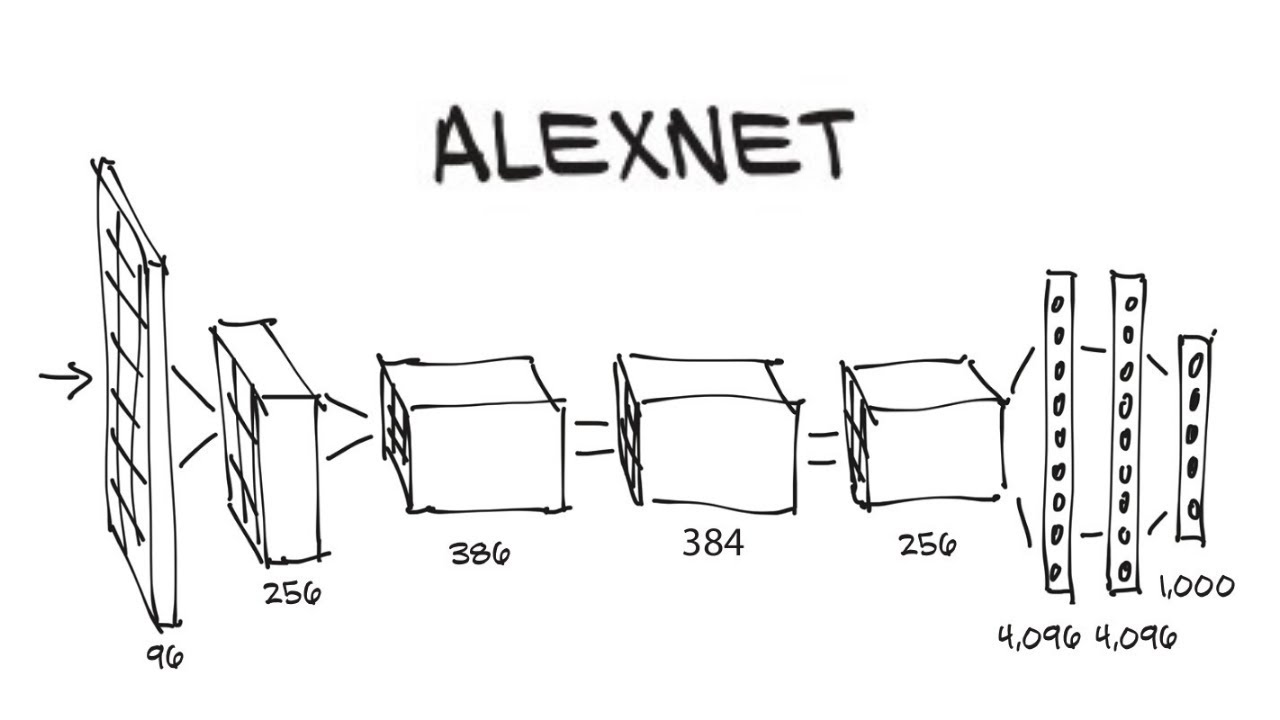
ALEXNET
IMAGENET üzerinde gerçekleştirilen ve her yıl düzenlenen, “bilgisayarlı görüyle tanıma” yarışmasında büyük başarı gösteren, öncü niteliğindeki evrişimsel sinir ağlarından biriydi ALEXNET. Model, Alex Krizhevsky, Geoffrey Hinton ve Ilya Sutskever tarafından yayınlanan bir çalışmaya dayanıyordu. ALEXNET, daha önce görülmemiş bir başarım oranına ulaştı yarışmada. Bu çalışmada yer alan Hinton, derin öğrenmenin gelişiminde önemli katkıya sahip isimlerden birisi olurken, Sutskever ismi ise daha sonra AlphaGo ve şimdilerde de OpenAI’da önemli bir aktör olarak karşımıza çıkmakta. Bu yönüyle ALEXNET, kesinlikle bir kırılma noktasıydı.
2014

Generative Adversarial Networks (GAN)
ALEXNET’i takip eden çalışmalarla birlikte artık “kedileri ayırt edebilen” modellere sahiptik . 2 yıl sonra ise bir başka büyük kırılma gerçekleşti. Google’da çalışan ve çiçeği burnunda bir bilgisayar bilimleri doktoru olan Ian Goodfellow önderliğindeki bir grup araştırmacının yayınlandığı makale, hem üretken yapay zeka hem de derin öğrenme uygulamalarının merkezinde yer alacak olan GAN çerçevesini çizmekteydi. Goodfellow daha sonra OpenAI, Apple ve DeepMind gibi yapay zeka ekosisteminin önemli oyuncuları olan şirketlerde, muhtelif rollerde tekrar tekrar karşımıza çıkacaktı. GAN yaklaşımı basitleştirilmiş bir anlatımla, “birbirini kandırmaya çalışan” iki yapay sinir ağının rekabetine dayalı olarak başarım oranını artırmayı hedefler. GAN çerçevesindeki iki sinir ağından biri, gerçek gibi görünecek yapay veri örnekleri üretirken, diğer sinir ağı ise kendisine sunulan veri örneklerinin gerçek mi yoksa yapay mı olduğunu tespit etmeye çalışır. Her iki ağ, diğerini ikna edecek kalitede çıktılar üretebilmek üzere iterasyonlar halinde kendilerini uyumlandırırlar.
2015

DeepDream
Google tarafından duyurulan bir bilgisayarlı görü uygulaması, 2015 yılında büyük ses getirdi. Alexander Mordvintsev isimli bir makine öğrenmesi araştırmacısının, bir önceki yılın ImageNet Challenge yarışması için geliştirilen Inception modelini temel alarak ortaya çıkardığı bu uygulama, bilgisayar ile resim üretme serüveninin başlangıcı açısından önemli bir köşetaşı teşkil etmektedir. DeepDream aslında resimleri işleyerek örüntü tanıması, özellikle de insan yüzlerini tanıması için geliştirilmişti. Ancak daha sonra, sistem tersine işletildiğinde, illüstrasyonlar üretilebildiği fark edildi. DeepDream’in ürettiği saykodelik ve Salvador Dali’nin stilini andıran görseller büyük ilgi gördü. DeepDream daha sonra açık kaynak olarak da kamuoyuyla paylaşıldı ve bu temel üzerine muhtelif uygulamalar geliştirildi.
2015

Diffusion
GAN sayesinde yaşanan hızlı gelişmelerin yanı sıra yeni bir sınırlılık da ortaya çıktı. GAN modelleri başarılı sonuçlar veriyordu ancak eğitilmeleri oldukça zahmetliydi. Üstelik bazen tüm olasılık dağılımını öğrenemiyor, bir alt kümeyle sınırlı kalacak şekilde sonuçlar üretiyorlardı. Örneğin hayvan resimleri üzerine eğitilmiş bir model, ısrarla köpek görselleri çıktı verebiliyordu. Bu noktada beklenmedik bir yerden, fizikten esinlenen yeni bir yöntem önerildi. Jascha Sohl-Dickstein liderliğindeki bir ekibin yayınladığı makale, dengesizlik termodinamiğindeki bir fenomeni, makine öğrenmesine uygulamayı teklif ediyordu. Difüzyon prensipleri, eğitim verisine ait olasılık dağılımına uygulanarak, yeni ve özgün görseller üretilebiliyordu. Difüzyonu tersten işleterek, gürültü(noise) şablonlarından anlamlı görsel örüntülere ulaşmak oldukça yenilikçi bir fikirdi ve işe yarıyordu.
2017
Transformer Mimarisi
Görsellerin algılanması ve üretilmesiyle ilgili birbiri ardına gelen StyleTransfer, Image-to-Image ve CycleGAN gibi önemli çalışmaların ardından, bir sonraki büyük sıçrama doğal dil işleme sahasında geldi. Daha önceleri dil işleme konusunda RNN ve CNN yaklaşımları yoğunlukta tercih edilmekteydi. Yine Google çatısı altında çalışan isimlerden birisi olan Ashish Vaswani liderliğindeki bir grup araştırmacının yayınladığı “Attention is All You Need” isimli makale, yeni bir mimariyi tanımlıyordu. Transformer yaklaşımında, Yinelemeli (RNN) ve Evrişimsel (CNN) sinir ağlarının aksine, “dikkat” mekanizması temele alınıyordu. Basitleştirilmiş bir anlatımla söylenecek olursa; model, girdi olarak verilen metnin parçalarını, üzerinde çalışılan göreve göre ağırlıklandırıyor ve göreve odaklı olarak her seferinde farklı bir kısmına yoğunlaşabiliyordu. Bu yöntemin, RNN ve CNN yaklaşımlarına göre daha verimli, daha ölçeklenebilir ve daha uzun metinlere uygun olduğu anlaşıldı. Doğal dilde komutları anlama, özet çıkarma, tercüme gibi işlevlerin yanı sıra, “doğal” algılanan metinler üretebilme kabiliyeti de Transformer Mimarisi‘nden sonra farklı bir boyuta geçiş yapabildi.
2018

Generative Pre-Training (GPT-1)
OpenAI tarafından geliştirilen GPT modellerinin başlangıcı olarak bu makale gösterilebilir. Bu tarihe kadar, doğal dil işleme modellerinin büyük çoğunluğu spesifik bir görev için eğitiliyor ve supervised learning (gözetimli öğrenme) ağırlıklı ilerliyorlardı. Alec Radford ve Ilya Sutskever‘in de aralarında yer aldığı araştırmacılar tarafından önerilen bu yeni yaklaşımda ise unsupervised learning (gözetimsiz öğrenme) bir ön eğitim (pre-training) vasıtası olarak kullanılıyor ve daha sonra spesifik amaçlara yönelik (sınıflama, duygu analizi vb) gözetimli öğrenme örnekleriyle model olgunlaştırılıyordu. İlk GPT modeli, 7000 adet yayınlanmamış kitaptan oluşan bir veriseti üzerinde eğitilmişti ve 117 milyon parametreye sahipti. Transformer mimarisini de implemente eden model, kendisi pek popüler olamasa da yaklaşmakta olan sansasyonel gelişmelerin ilk adımıydı.
2019

BERT Destekli Google Aramaları
Google, üretken yapay zeka çalışmalarının merkezinde yer almaya devam etti. “Bidirectional Encoder Representations from Transformers” ya da kısaca BERT olarak adlandırılan bir model duyuruldu ve hatta açık kaynak olarak sunuldu. Google’a göre bu teknoloji sayesinde oldukça isabetli yanıtlar üreten bir soru-cevap etkileşimi mümkün olacaktı. Paylaşılan bir blog yazısı ile, BERT’in, Google Arama sonuçlarında sağladığı kaydadeğer iyileşmeden örnekler verildi. Buna göre, transformer tabanlı bir yaklaşıma sahip olan BERT, kullanıcıların girdiği arama metinlerini, klasik web aramalarındaki gibi yalnızca anahtar kelime eşleştirmeleri yapmak için kullanmıyordu. Her bir kelimenin, o cümlenin bağlamı içerisindeki anlamı hesaba katılarak arama yapabilmek mümkün hale gelmişti.
2019
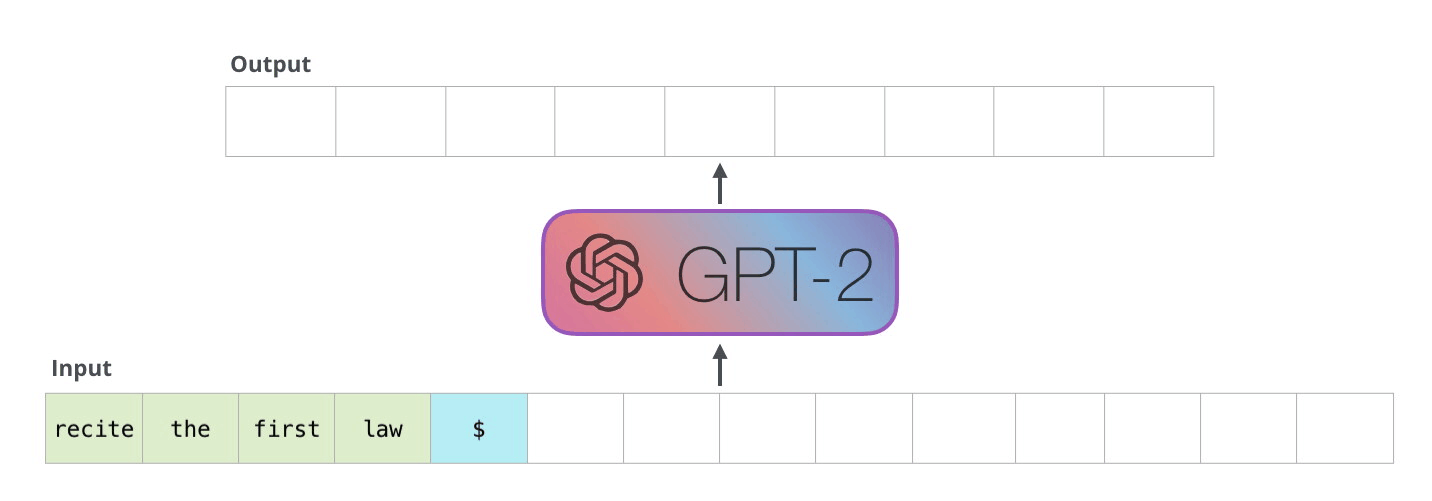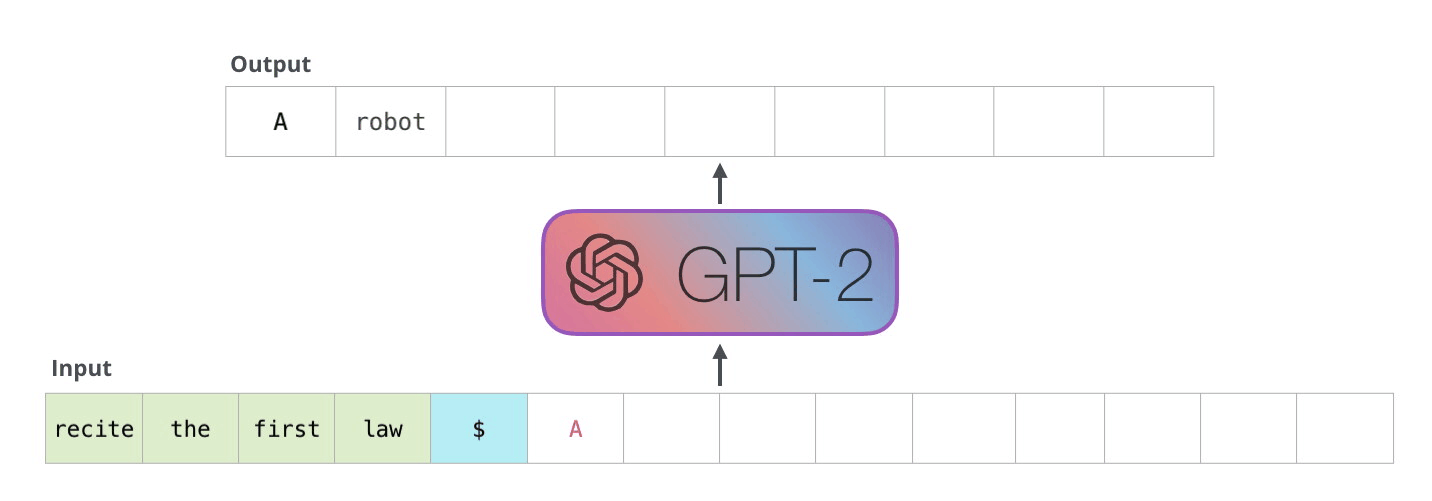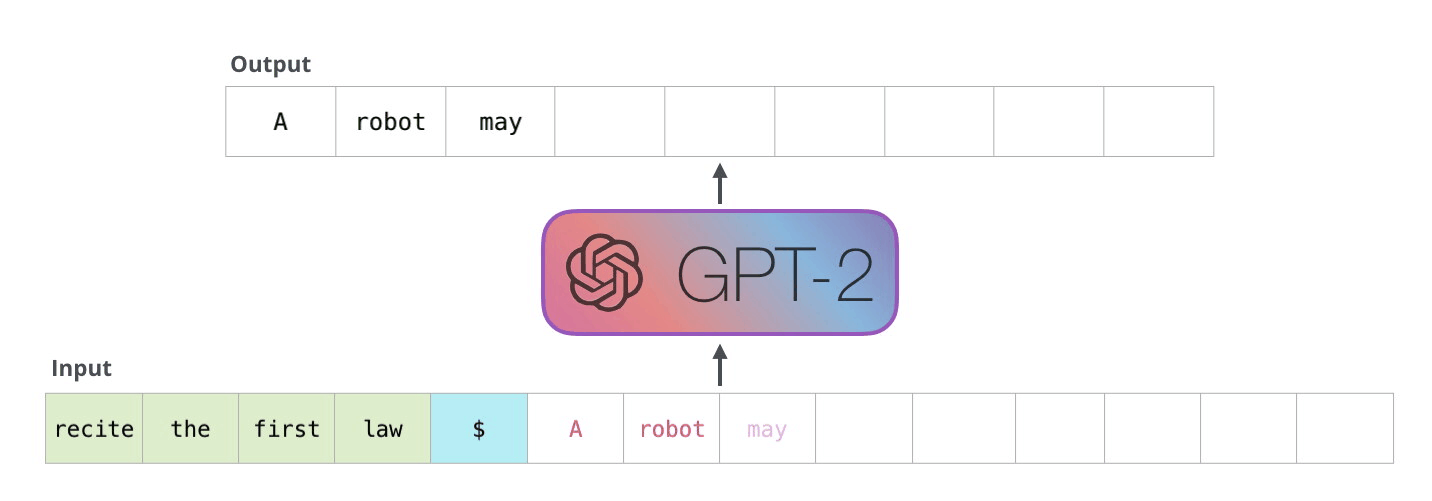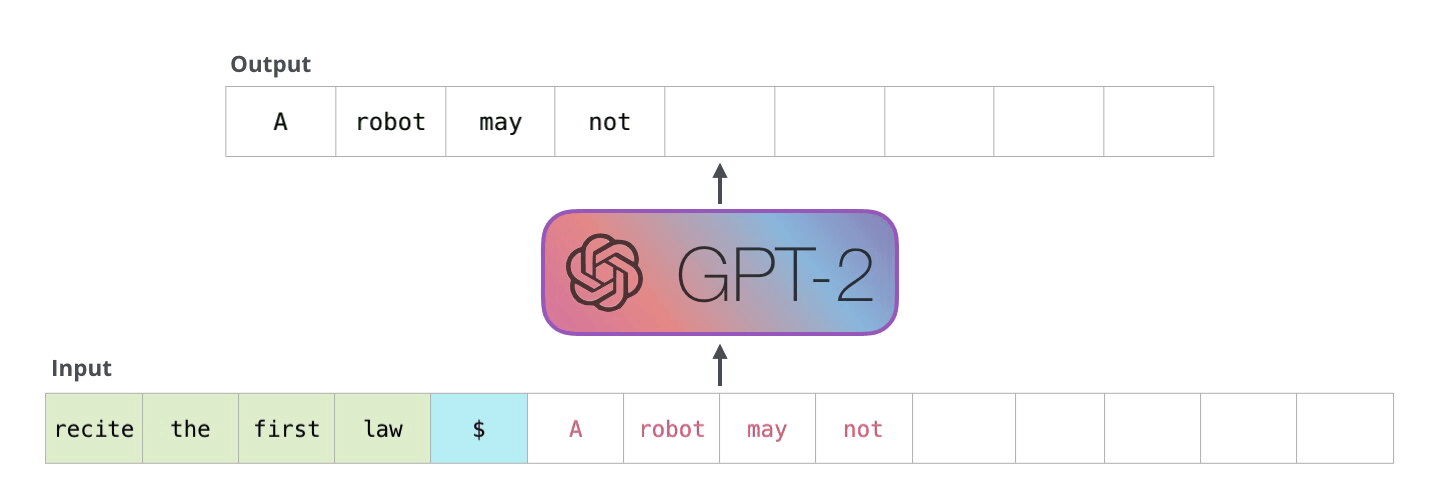
GPT-2
GPT-1 ile oluşturulan temel yapıda minör değişiklikler (çoklu görev senaryoları eklendi) yapılarak ölçek konusuna odaklanıldı. GPT-1’e göre çok daha büyük bir veriseti ve çok daha fazla parametre ile oluşturulan GPT-2, selefine kıyasla çok daha başarılı sonuçlar verdi. Parametre sayısı 117 milyondan 1.5 milyara yükselmişti ve bu kez veriseti olarak WebText kullanılmıştı. WebText, popüler sosyal mecra Reddit’ten scrap edilen (çıkarılan) verilere dayanıyordu. Özellikle en çok upvote alan/en popüler maddelerin içerdiği harici linklerde yer alan içerikler de verisetine dahil ediliyordu. Böylece 8 milyondan fazla doküman içeren yaklaşık 40 gigabyte büyüklüğünde bir eğitim veriseti ile yeni modeller eğitildi. Aslında 117 milyon, 345 milyon, 762 milyon ve 1.5 milyar parametreye sahip 4 model ile çalışılmıştı ve 1.5 milyar parametreli model tüm başarı kriterlerinde diğerlerini gölgede bırakmıştı. GPT-2 bu yönüyle, mevcut model mimarisinin, daha geniş bir veri havuzu ve parametre kümesiyle daha iyi sonuçlar verebildiğini göstermişti. Hatta GPT-2, kullanılan verisetine “underfit” etmişti. Dolayısıyla daha büyük ölçekli bir model geliştirmek oldukç makul bir sonraki adım seçeneğiydi. GPT-2 ile ilgili önemli bir diğer karakteristik ise “zero-shot” odaklı olmasıydı. Yani, eğitim verisinde birebir örneği yer almayan örnekleri de doğru biçimde anlamlandırabilen bir model hedeflenmişti.
2020

GPT-3
GPT serisinin üçüncü versiyonu, tüm dünyanın COVID-19 pandemisiyle sarsıldığı günlerde duyuruldu ve belki de bu yüzden yeterince ses getiremedi. Ancak yine de teknoloji dünyasında, özellikle de yazılım geliştiricileri arasında büyük ilgi uyandırdı. Çünkü GPT-3, seleflerinin yaptığı özetleme, tercüme, sınıflandırma gibi görevlerin yanı sıra, insan üretimi gibi duran uzun metinler yazabilme kabiliyeti ve birçok farklı programlama dilinde kod yazabilme yetenekleriyle herkesi şaşkınlığa uğratmıştı. GPT-2 tecrübesinden sonra yeni modelin çok ciddi bir ölçek genişlemesi üzerine kurulacağı bekleniyordu. Nitekim öyle de oldu. GPT-3 modeli çok daha geniş bir veriseti üzerinde eğitilmişti ve 175 milyar parametreye sahipti. Verisetinin ana omurgasını WebText2 adı verilen küme oluşturuluyordu. Bu veri kümesi yaklaşık 45 terabyte büyüklüğündeydi ve web üzerinde genel erişime açık haberler, bloglar, forumlar gibi birçok farklı sayfadan derlenmişti. Bunun yanı sıra, 11.000 kitaptan oluşan yeni BookCorpus ve özel derlemelere dayanan Wikipedia ile Common Crawl veri kümeleri de farklı ağırlıklar atanarak eğitim verisine dahil edilmişti. Böylesi bir eğitim süreci; aylarca süren, yoğun ve ileri düzey mühendislik eforları ile benzerine az rastlanır büyüklükte bir işlem gücünün bu göreve tahsis edilmesi sayesinde mümkün oldu. Ölçeğin büyümesinin yanı sıra yeni modelde vurgulanan özellik bu defa multitasking yerine few-shot learning idi. Yabi bu versiyonda, “az sayıda örnekten yola çıkararak öğrenmenin genellenmesi” üzerinde durulmaktaydı. Sonuçlar da bununla uyumluydu. GPT-3 ile sofistike metinler yazılabiliyor, doğal dilde verilen komutlarla kod yazma pratiği yazılım geliştirme sürecine yepyeni ihtimallerin kapısını aralıyordu. Elbette bu önemli gelişmelerin yanı sıra GPT-3 kaydadeğer sınırlılıklara da sahipti. En önemlisi, gerçek olmayan veriler veya irrasyonel görüşler üretebiliyordu model. Üstelik de bunu oldukça özgüvenli bir uslupla yapıyordu. Bir diğer önemli sınırlılık da modelin önceki etkileşimleri hesaba katabilmesini sağlayan bağlam limitinin dar oluşuydu. Yine de GPT-3 halihazırda API desteğine sahip en gelişmiş Large Language Model (geniş ölçekli dil modeli) konumunda ve GPT-3 etrafında SaaS tabanlı yeni bir start-up ekosistemi hızla büyümekte [Yeni oluşan Generative AI pazarına ilişkin öngörüler/çalışmalar: 1) Sequoia, 2) Sequoia IMG, 3) Antler, 4) Base10, 5) AI Multiple
2021

DALL-E
GPT serisi ile metin çıktılarına odaklanan OpenAI, orada edinilen bilgi birikimini yeni bir sahaya, resim üretme kabiliyetine taşıdı. Salvador Dali ve popüler animasyon filmi WALL-E isimlerinin bir kombinasyonu olarak bu yeni modele DALL-E adı verildi. DALL-E, metin-resim ikililerinden oluşturulan bir veriseti üzerinden eğitilmiş, GPT-3 modelinin 12 milyar parametreli bir versiyonundan ibaretti. Bu model sayesinde metin girdilerinden yola çıkarak, bu girdilerle ilişkili görseller üretilebiliyordu. Birebir eşleşme olarak açıklanabilecek çıktıların yanı sıra (örneğin; “araba” metni girildiğinde bir araba çizmek) DALL-E’nin yapabildiği bir başka eylem sonraki modeller için heyecan uyandırıyordu. Bu yeni model, birbiriyle doğrudan ilgisi olmayan kavramları alıp birlikte anlamlı olacakları bir bağlamda resmedebiliyordu (örneğin; “akordiyondan yapılmış bir hayvan” metni girildiğinde buradaki kastı anlayarak bir hayvanı akordiyon formuyla kombine ederek resmetmek). Bir transformer yaklaşımına dayanan DALL-E, görsellerde bulunabilecek perspektif, yerleşim, renk gibi pek çok elementi anlayabiliyor ve bu elementler arasında ilişki kuran metinleri (örnek: bir küpün üzerinde bulunan kırmızı kedi) çözümleyerek buna uygun görsel çıktıyı üretebiliyordu.
2021

CLIP
Bu çalışma OpenAI tarafından genel erişime açıldı ve metinden resim üretme sahasında hızlı gelişmeler yaşanmasını sağlayan süreci başlattı. Contrastive Language-Image Pre-training ya da kısaca CLIP modeli bilgisayarlı görü alanındaki önemli ilerlemelere rağmen en çok zorluk çekilen iki noktaya dikkat çekiyordu. Derin öğrenme tabanlı mevcut yaklaşımlarda gözetimli öğrenme için eğitim verisi üretmek oldukça zahmetliydi ve modellerin bu veri dışına genelleyebilme kabiliyeti sınırlı kalıyordu. Doğal dil üzerine odaklanmış olan OpenAI, aynı yaklaşımın bu problemlere alternatif bir çözüm getirebileceğine inanıyordu. Buna göre; insanlar tarafından bilhassa etiketleme yapılmış veri örnekleri yerine, internette bolca bulunan ham metinlerle resimler arasındaki ilişkiden yola çıkıldı. İnternetten derlenen 400 milyon metin-resim ikilisinden oluşan bir veri seti üzerinde eğitilen modelin hangi metinsel tanımlamanın hangi resimle uyumlu olabileceği konusunda isabetli kestirimler yapabildiği görüldü. CLIP ile birlikte gelen belki de en önemli gelişme, başka çalışmaların da artık göreve özgü veri seti oluşturma ihtiyacı olmaksızın kendi sınıflandırma modellerini geliştirebilmeleri oldu. Bu kazanım, metinden resim üretme araçlarının hem sayıca hem de performans olarak atılım yapması şeklinde karşımıza çıktı ilerleyen süreçte.
2022

Midjourney
Midjourney kısa süre içerisinde, metinden resim üreten modeller/araçlar arasında kendisine özel bir yer edinmeyi başardı. Bu zaman çizelgesine girdinin yapıldığı Şubat 2023 itibarı ile Midjourney benzer araçlar içerisinde tartışmasız en başarılı olanı. Hem çok daha az girdi mühendisliği gerektirmesi hem de oluşturduğu görsellerin etkileyici düzeydeki kalitesi açısından henüz rakipleri kendisine yaklaşabilmiş değil. Midjourney’e özel bir yön katan bir başka husus da bu aracı mümkün kılan modelin tam bir muamma olması. Midjourney kendi modelini ticari değeri sebebiyle tamamen gizli tutuyor. Nasıl çalıştığına dair ancak tahmine dayalı uzman görüşleri var. Yaygın iki kabul şöyle: a) Temelde Stable Diffusion’a dayanıyor b) Çok başarılı bir doğal dil işleme katmanı var ve bu katman kullanıcının verdiği girdiye titiz bir girdi mühendisliği uyguladıktan sonra görsel üretme adımına geçiyor. Ancak tüm bunlar spekülasyondan ibaret. Midjourney her yönüyle farklı bir araç. Diğerlerinin aksine kendine ait bir web uygulaması ya da kendi bilgisayarınızda çalıştırabildiğiniz bir sürümü yok. Modelle etkileşim, Discord sunucuları üzerinden kuruluyor. Bu alışılmadık kullanıcı deneyimine rağmen sunduğu sonuçlar sayesinde hem ilgi hem de gelir toplamayı başarabiliyor. Özellikle Versiyon 4 ile birlikte profesyonel olarak yapay zeka tabanlı görsel üreten herkesin ilk tercii olmayı başardı. Midjourney ile ilgili enteresan bir başka konu da arkasındaki ekip. Daha önce Leap Motion ile yenilikçi bilgisayar-insan etkileşimi aparatları geliştirmek üzerine çalışmış olan David Holz’un yönettiği, kendi ifadeleriyle “sadece 11 kişiden oluşan bir bağımsız araştırma laboratuarı”nın eseri Midjourney.
2022

DALL-E 2
DALL-E modelinin yeni versiyonu için 2022’de aniden gelişen üretken yapay zeka dalgasını başlatan ilk işaret fişeği oldu. Midjourney henüz geniş kitlelerce fark edilmemiş ve bugünkü performansına erişmemişken, DALL-E 2’nin “ata binen astronot”u ikonik bir simgeye dönüşmeye başladı. Öncelikle teknoloji medyasında daha sonra ise sosyal medya üzerinden her kesimden insanda ilgi uyandırdı. DALL-E 2’nin çıkışından bir süre sonra duyurduğu Inpainting ve Outpainting işlevleri de en az metinden resim üretme kabiliyeti kadar ilgi çekiciydi. Böylece yapay zeka tarafından üretilen görsellerin yine yapay zeka tarafından, içerdikleri öğelerle uyumlu ve kullanıcı girdisine göre şekillendirilebilen bağlamlara yerleştirilebilmesi ya da görsellerin kısmi olarak modifiye edilmesi mümkün hale geldi. DALL-E 2, önceki DALL-E modeline göre daha yüksek çözünürlükte görseller üretebiliyor ve metin girdilerini daha iyi anlamlandırabiliyordu. Bu model, 2 parçalı bir yapıdan oluşuyor. Prior olarak isimlendirilen aşamada, metin girdisinin bir görsele dönüştürülmesi sağlanırken Decoded olarak anılan ikinci aşamada ise bu görselin önemli unsurlarına ağırlık verilerek çizdirilmesi sağlanıyor. Bu kompleks sürece en anlaşılır biçimde özetleyen makalelerden birisi şurada. DALL-E 2’yi halihazırda diğer metinden resim üretme modellerinden ayıran bir diğer özellikse API desteğiyle programatik olarak kullanımının mümkün olması. Böylece, üretken yapay zeka destekli görsel oluşturma işlevi için mevcut en iyi alternatif durumunda.
2022

Stable Diffusion
2022 yılı metinden resim üretme işlevinin altın yılı oldu. Midjourney ve DALL-E 2 ticari modellerdi ve ücretli kullanım senaryolarıyla sunulmuşlardı. Bu alandaki ilk açık kaynak olarak sunulan ve kendi bilgisayarınızda/sunucunuzda da çalıştırabileceğiniz model ise Stable Diffusion oldu. Stability AI isimli bir start-up tarafından geliştirilen bu model daha sonra pek çok farklı grup tarafından farklı varyasyonlar şeklinde birçok yeni araca temel teşkil etti. Stability AI ise kendi varyasyonunu Dream Studio adıyla ve ücretli olarak hizmete sundu. Stable Diffusion duyurusu, ortaya çıkan sonucun tam bir kolektif çalışma olduğunu ifade ediyordu. Latent Diffusion çalışması üzerine inşa edilen yeni modelde birçok önemli yapay zeka aktörünün katkısı vardı (RunwayML, Compvis, Eleuther). Açık kaynak bir metinden resim üretme modeli yeni ihtimalleri deneme fırsatı sundu geliştiricilere. Birçok farklı konuda özelleşmiş birçok farklı stile göre ayarlanmış stable diffusion varyantı bulmak mümkün.
30/11/2022

ChatGPT & GPT 3.5
Üretken yapay zeka ile ilgili peşpeşe yaşanan gelişmeler içerisinde belki de “milat” olarak değerlendirilecek olay, ChatGPT’nin genel erişime açık olarak yayınlanması oldu. Zira, OpenAI ekibinin de tahmin edemediği, hiç beklenmedik ve daha önce benzeri pek görülmemiş bir ilgiyle karşılandı bu yeni sohbet ara yüzü. Geniş ölçekli dil modellerinin kabiliyetleriyle ilgili gelinen noktayı deneyimleyen herkes etkilendi. Öyle ki ChatGPT 1 milyon ve 100 milyon kullanıcı sayılarına bugüne kadar en hızlı erişen teknolojik araç oluverdi. ChatGPT ile birlikte gelen kamuoyu, medya ve yatırımcı ilgisi, üretken yapay zeka alanında geliştirilen diğer model ve araçlar için de büyük bir doping etkisi yaptı. Bu alanın yepyeni bir ekosistem olarak ortaya çıkmasına giden süreç böyle başladı. Bu zincirleme reaksiyonu yaratan modele yakından bakacak olursak, Instruct GPT temelli olarak özelleştirilen ve GPT 3.5 olarak nitelendirilen geniş ölçekli dil modelinin bir sohbet ara yüzüyle sunulmasından ibaret olduğunu görüyoruz. GPT 3.5, GPT-3 üzerine bir fine-tuning çalışmasıyla oluşturuldu. Bu safhada hem Supervised Learning hem de RLHF (Reinforcement Learning With Human Feedback) yaklaşımı kullanılarak ChatGPT’nin sohbet tarzı iletişimlerdeki performansı artırıldı. Bunun yanı sıra ChatGPT ile birlikte GPT 3.5 modeline dayanan bir diğer varyant da text-davinci-003. Bu varyant bir web ara yüzü olarak değil, API üzerinden erişilebilen bir servis olarak sunuldu. GPT 3.5 ailesinin dolayısıyla ChatGPT’nin iki önemli kısıtı mevcut: Modellerin baz aldığı veriler 2021 Eylül’ünde sona erdiği için bu tarihten sonraki gelişmelerle ilgili yanıt üretemiyor ya da hatalı yanıtlar verebiliyorlar. Ayrıca OpenAI, bu modelin internete doğrudan erişimini kısıtlayarak erişime açmayı tercih ettiği için anlık veriler üzerine de yorum yapamıyorlar. Oluşan ilgiyi takiben daha sonra ChatGPT’nin “Plus” versiyonu ücretli olarak sunulmaya başlandı.
6/2/2023

GEN-1
RunwayML, Stable Diffusion ve bunun öncüsü olan Latent Diffusion modelin geliştirilmesinde aktif rol alan isimlerin öncülüğünde oldukça etkileyici yetenekler sunan bir platform. Runway ismini ilk olarak yapay zeka destekli video ve resim işleme araçlarıyla duyurdu. 2023 yılı başında gelen bir duyuru ile de üretken yapay zeka teknolojilerinin görece daha yavaş mesafe kat ettiği video sahasında büyük ses getiren yeni modelleri GEN-1 için erken erişim duyurusu yaptılar. Öncelikle Midjourney’nin yolundan giderek Discord üzerinden bir bot marifetiyle kullanıma açılan GEN-1 daha sonra RunwayML platformunda profesyonel bir kullanıcı ara yüzüyle erişilebilir hale geldi.
GEN-1, videodan videoya stil transferi konusunda gösterdiği başarılı performansla adından söz ettirdi ve üretken yapay zekanın video üretimi konusundaki potansiyeline dair kuşkuları da büyük ölçüde hafifletti. GEN-1 teknolojisi, girdi olarak verilen bir videonun görünümünü iki farklı senaryoda değiştirebiliyor: a) Bir resim, kılavuz olarak verildiğinde, görselde yer alan görsel stil öğelerini videoya uyguluyor. Bu düzenlemeye metinsel girdilerle de boyut kazandırılabiliyor aynı süreçte b) Yalnızca metinsel girdilerle videonun stil özellikleri belli oranda değiştirilebiliyor. GEN-1’in en temel kısıtı ise şimdilik yalnızca 3 saniye uzunluğunda video işleme yapabilmesi.
GEN-1 ile birlikte duyurulan makalede, çalışma prensiplerine dair ayrıntılı bilginin yayınlanmış olması da üretken yapay zeka komünitesi açısından sevindirici bir gelişme oldu. Bu kompleks süreç özetle; bir videonun “içerik” ve “yapı” olarak sınıflanan özelliklerinin, Latent Diffusion tabanlı bir omurga üzerinde metin ve/veya resim girdilerine paralel şekilde işlenmesine dayanıyor. Burada teklif edilen yaklaşımla, uzam ve zaman açısından tutarlı bir modifikasyon gerçekleştirilebiliyor.
10/2/2023

ControlNet
GEN-1 ile aynı dönemde duyurulan bir diğer heyecan verici gelişme ise ControlNet oldu. Stable Diffusion’ın yeteneklerini bir adım ileriye taşıyan bu varyant sayesinde, üretilen görseller üzerinde daha fazla kontrole sahip olmak mümkün oldu. Orijinal Stable Diffusion modelinde, kullanıcıdan alınan metin girdisi tüm difüzyon süreci boyunca ayarlama/yakınsama yapmak için kullanılmakta. ControlNet bu ayarlama/yakınsama sürecine yeni bir katman ekledi. Bu katmanda, girdi olarak alınan görseldeki bazı önemli unsurlar (keskin kenarlar, karakterin pozunu gösteren noktalar, düz ve devamlı çizgiler vb) tespit edildikten sonra, kullanıcının metin girdisine ek yeni bir “kılavuz” olarak ayarlama/yakınsama işlemi gerçekleştirilmekte. ControlNet GitHub reposuna buradan, modele dair ayrıntılı ve yalın bir anlatıma ise şuradan erişebilirsiniz.
Bu yetenek hızlı biçimde pek çok kullanım alanı buldu. Özellikle görsellerde yer alan karakterlerin postür ve konumlarını metin girdileriyle kontrol etmek noktasında tatmin edici örnekler üretildi. Bu yeni sinir ağının getirdiği kabiliyetler daha sonra video üretimi senaryolarında da kullanılmaya başlandı. Üretken yapay zeka ile oluşturulan kreatif içeriklerdeki en temel problemlerden biri olan devamlılık ve tutarlı biçimde görseli düzenleyebilme ihtiyacı açısındna ControlNet, oldukça umut vaat eden bir kapıyı aralamış oldu.
Bu zaman çizelgesinin hazırlanmasında kendi okumalarım, derlemelerim ve notlarıma ek olarak aşağıda listelenen kaynaklardan faydalandım:
Curation of Important Papers by Dr. Alan Thompson
Timeline of Text-to-Image Machine Learning Models by Fabian Mosele
Intelligence is not Artificial by Piero Scaruffi
NOT: Üretken Yapay Zeka teknolojilerinin gelişim sürecinde çok daha fazla ana başlık ele alınabilir. Bu çalışma, Ocak 2023 itibarı ile bu alanın geldiği noktada öne çıkan / popüler hale gelen boyutlara odaklanarak oluşturulmuştur.